刷题记录
- 491. 非递减子序列
- 46. 全排列
- 47. 全排列 II
- 去重写法一
- 去重写法二
491. 非递减子序列
leetcode题目地址
本题对于去重是一个难点,因为题目不允许排序,所以需要加一个笔记数组来判断相同的元素在同一层是否已经使用。使用set、map都可以达到这个目的。
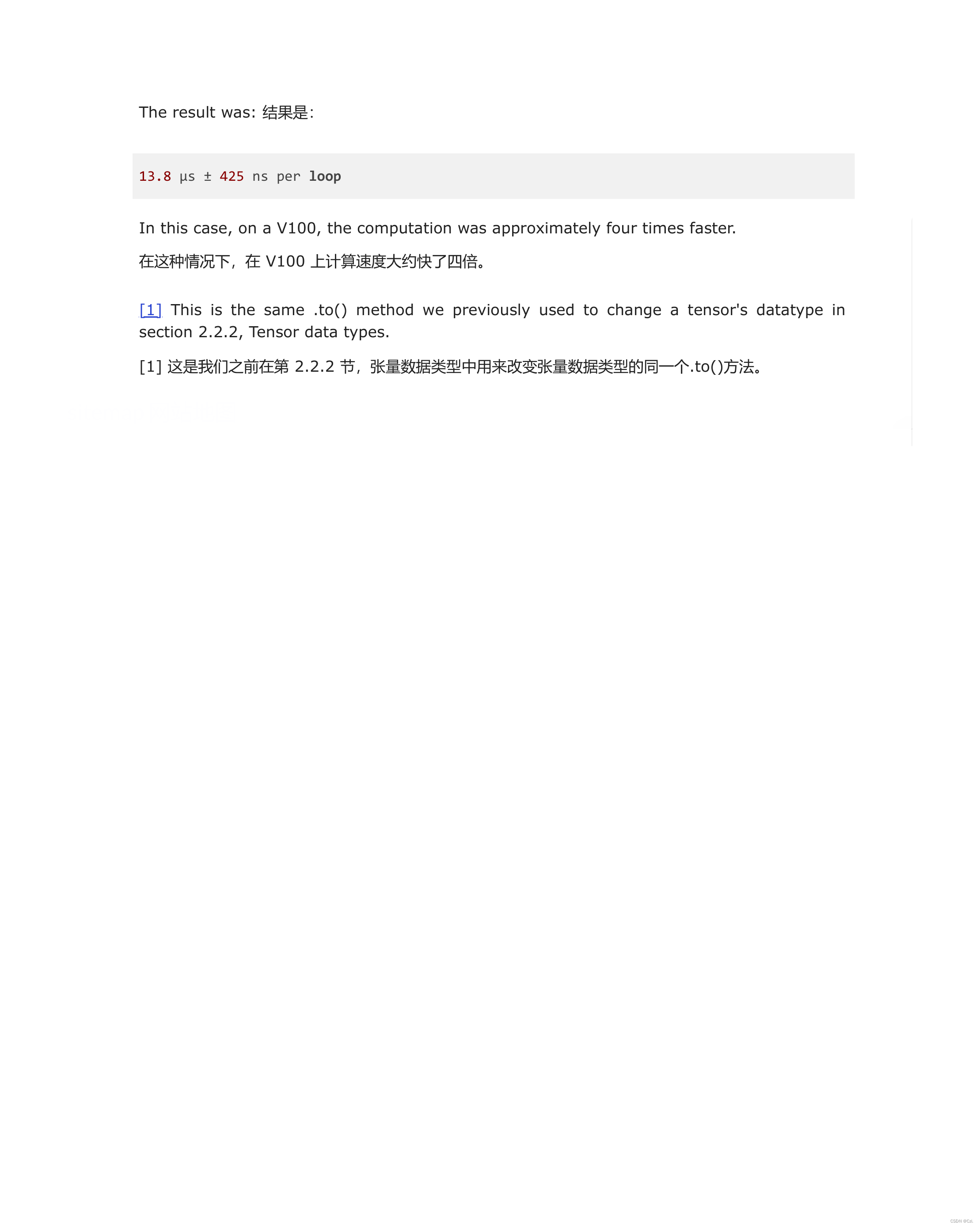
时间复杂度:
O
(
n
∗
2
n
)
O(n * 2^n)
O(n∗2n)
空间复杂度:
O
(
n
)
O(n)
O(n)
// c++
class Solution {
public:
vector<int> cur;
void backtracking(vector<vector<int>> &result, const vector<int>& nums, int left){
if(cur.size()>1){
result.emplace_back(cur);
}
// 负责本层的去重
unordered_set<int> uset;
for(int i=left; i<nums.size(); i++){
// 去重
if(uset.find(nums[i])!=uset.end()) continue;
if(cur.size()==0 || cur[cur.size()-1] <= nums[i]) {
cur.emplace_back(nums[i]);
uset.insert(nums[i]);
backtracking(result, nums, i+1);
cur.pop_back();
}
}
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
vector<vector<int>> result;
backtracking(result, nums, 0);
return result;
}
};
46. 全排列
leetcode题目地址
全排列无需记录起始位置(每层都是从头开始找未使用过的元素),只需要控制每个元素在每个排列中只使用一次。借助一个额外的数组或map来实现。
时间复杂度:
O
(
n
!
)
O(n!)
O(n!)
空间复杂度:
O
(
n
)
O(n)
O(n)
// c++
class Solution {
public:
vector<int> cur;
unordered_map<int, int> used;
void backtracking(vector<vector<int>>&result, const vector<int>& nums){
if(cur.size()==nums.size()){
result.emplace_back(cur);
return;
}
for(int i=0; i<nums.size(); i++){
if(!used[i]){
cur.emplace_back(nums[i]);
used[i] = 1;
backtracking(result, nums);
used[i] = 0;
cur.pop_back();
}
}
}
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int>> result;
backtracking(result, nums);
return result;
}
};
47. 全排列 II
leetcode题目地址
本题在上一题的基础上加入了相同的元素,因此需要对相同元素发起的全排列进行去重,有两种写法,一种是借助一个数组或容器来标识当前层是否已经使用了与当前元素相同的元素;另一种是排序过后判断前一个搜索过的元素与当前元素是否相同。
时间复杂度:
O
(
n
!
∗
n
)
O(n! * n)
O(n!∗n)
空间复杂度:
O
(
n
)
O(n)
O(n)
去重写法一
// c++
class Solution {
public:
vector<int> cur;
// 纵向 标识单个排列中当前元素是否使用
unordered_map<int, int> used;
void backtracking(vector<vector<int>>&result, const vector<int>& nums){
if(cur.size() == nums.size()){
result.emplace_back(cur);
return;
}
// 横向 标识所有排列中与当前元素相同的值是否已经参加过查找
unordered_set<int> duplicate;
for(int i=0; i<nums.size(); i++){
if(!used[i] && duplicate.find(nums[i])==duplicate.end()){
used[i] = 1;
duplicate.insert(nums[i]);
cur.emplace_back(nums[i]);
backtracking(result, nums);
cur.pop_back();
used[i] = 0;
}
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
vector<vector<int>> result;
backtracking(result, nums);
return result;
}
};
去重写法二
// c++
class Solution {
public:
vector<int> cur;
// 纵向 标识单个排列中当前元素是否使用
unordered_map<int, int> used;
void backtracking(vector<vector<int>>&result, const vector<int>& nums){
if(cur.size() == nums.size()){
result.emplace_back(cur);
return;
}
for(int i=0; i<nums.size(); i++){
if(i>0 && nums[i]==nums[i-1] && used[i-1]) continue;
if(!used[i]){
used[i] = 1;
cur.emplace_back(nums[i]);
backtracking(result, nums);
cur.pop_back();
used[i] = 0;
}
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(), nums.end()); // 排序
vector<vector<int>> result;
backtracking(result, nums);
return result;
}
};